
편리한 GUI 기반 설계, 뛰어난 확장성 및 연결성을 기반으로 대용량 데이터를 신속하게 처리할 수 있는 솔루션입니다.
데이터를 쉽게 이해하고, 정리하며, 모니터링하고 변환할 수 있도록 지원하는 선도적인 데이터 통합 플랫폼으로, 유연한 확장성과 대량 병렬 처리(MPP) 기능을 제공합니다.
또한 코딩 없이도 사용 가능한 직관적인 GUI를 제공하며, 다양한 형태의 데이터를 클라우드 환경에서도 신속하고 편리하게 통합할 수 있는 강력한 엔진을 갖추고 있습니다.
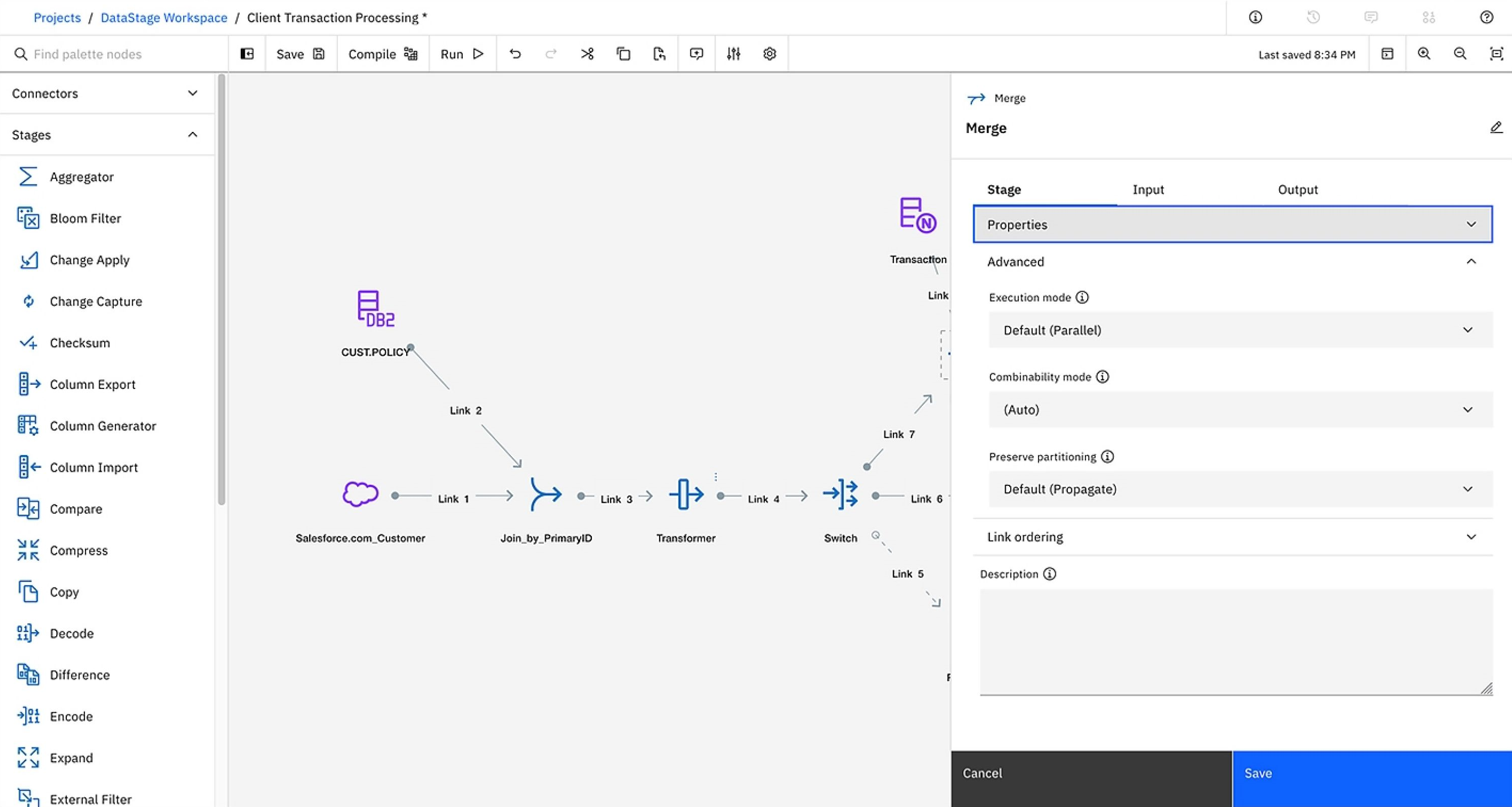
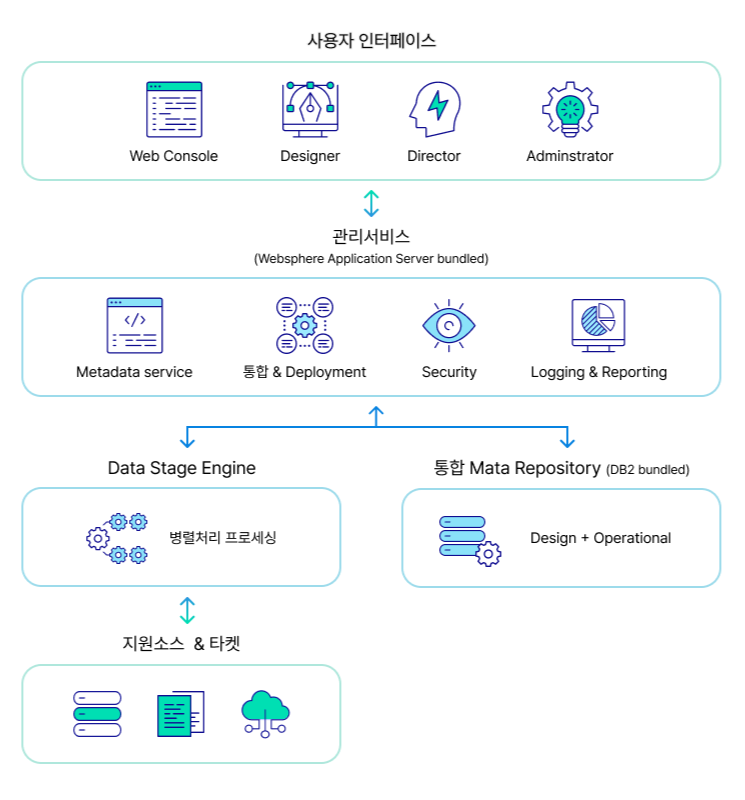
IBM InfoSphere DataStage는 IBM Information Server 아키텍처를 기반으로 운영되며, 공통 서비스와 다양한 Connectivity, 통합 메타데이터를 지원합니다.
개발 중 등록된 테이블 메타 정보, 개발된 프로그램 정보, 그리고 운영 중 발생하는 각종 정보는 중앙 저장소(Repository)에 저장되어 다중 사용자 환경을 지원합니다.
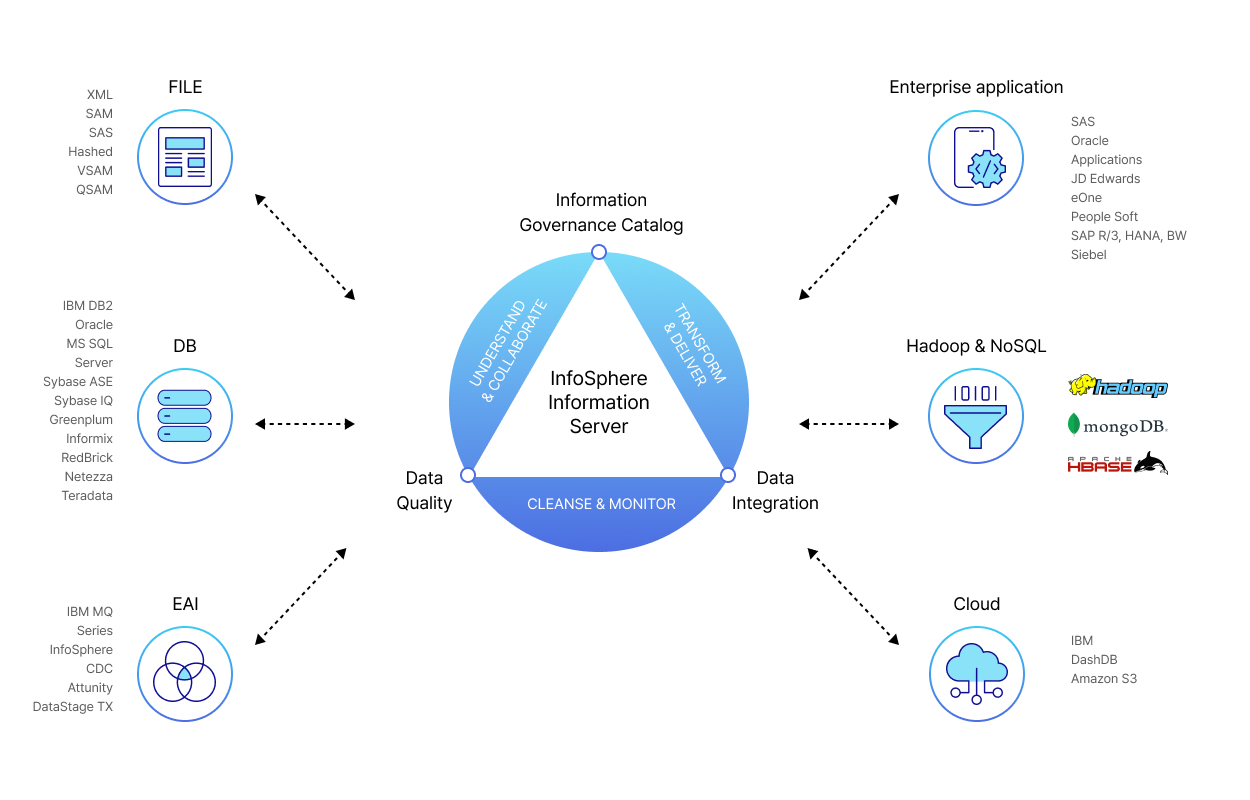
Infosphere DataStage는 다양한 형태의 소스와 타겟을 지원하며, 단일 Job에서 이기종 소스와 타겟을 동시에 액세스하여 데이터를 추출, 통합, 가공, 적재할 수 있는 ETL 솔루션입니다. 기본적으로 Any Source, Any Target을 지원하므로 다양한 환경에서 유연하게 사용할 수 있습니다.




| 구분 | 기존 개발 방식 | IBM DataStage 적용 방식 |
|---|---|---|
| 생산성 | 각 플랫폼과 데이터 포맷에 맞춰 개발 및 디버깅에 많은 인력과 시간이 소요되며, 테스트와 결과 검증에도 많은 노력이 필요함 | 통합된 GUI 환경에서 Top Down 방식으로 손쉽게 이행 로직을 구현할 수 있으며, 자동 디버깅 기능을 통해 개발 시간과 인력을 절반 이상 단축할 수 있음 |
| 프로젝트 관리 |
여러 개발자가 다른 환경에서 프로젝트를 진행하므로 체계적 관리와 표준화가 어렵고, 진척도 파악이 복잡함 | 통합된 환경에서 Project 및 Job 단위로 작업을 관리하며, 메타데이터 공유와 품질 관리로 표준화와 진척도 관리를 쉽게 수행할 수 있음 |
| 데이터 품질 개선 |
모니터링을 통한 소스 데이터 검증 체계가 부족해, 최초 로직으로 구현된 검증 기준 외에 지속적인 기능 향상이 어려움 | 소스 데이터 오류를 유형별로 분류하고 체계적으로 관리해 근본적인 오류 원인을 제거하며, 지속적인 데이터 품질 개선 가능 |
| 데이터 오류 대응 |
일괄 처리 방식으로 데이터 갱신 중 발생한 오류에 대해 즉각적으로 대처하기 어려움 | 데이터 오류 발생 시 실행을 중단하고 오류를 수정한 후 재실행할 수 있어, 오류에 대한 즉각적인 대처가 가능함 |
| 데이터 이행 요건 변경 |
소스 데이터나 타겟 DB의 요건 변경 시 관련 프로그램을 수작업으로 수정해야 하며, 변경 대상 파악이 어렵고 시간이 많이 소요됨 | 메타DB를 통해 변경 대상을 정확히 파악하고 데이터 매핑 규칙을 수정하여 이행 프로그램을 자동으로 재생성할 수 있음 |
| 데이터 이행 모니터링 |
타겟 DB 갱신 정확성을 주기적으로 수동 확인해야 하며, 불일치 발생 시 원인 파악이 어려움 | 솔루션의 모니터링 기능을 통해 작업 성공/실패 여부와 처리 건수를 쉽게 모니터링하고, 수행 로그를 통해 불일치 원인을 신속하게 파악할 수 있음 |



© 2024 Zalesia ALL RIGHT RESERVED




